
Bioinformatics Segment Manager, Agilent Technologies
BIOGRAPHY
MAY 13, 2015 1:30 PM PDT
Agilent platform for genomics, transcriptomics, proteomics and metabolomics based integrated biology: challenges and tools for multi-omics research
Presented at:
Genetics and Genomics Virtual Event Series 2015
Speaker
Abstract
Biological datasets have become increasing large and complex. Knowledge databases and publicly available datasets are available for use in experimental planning and running results comparisons However, this often requires a number of different software and is very time consuming. This difficulty becomes immediately apparent when handling multi-omic data trying to merge genomic, transcriptomic, proteomic or metabolomic information. GeneSpring software suite provides a platform for multi-omic data analysis allowing for comparisons and results interpretation across different platforms and technologies. An integrated pathway approach for analyzing multi-omic data can significantly alleviate bottlenecks and provide valuable information that is often missed in individual experiments. One successful method for translating diverse analytical data into biological understanding can be achieved by projecting and visualizing pairs of experimental data onto curated biological pathways (WikiPathways/BioCyc/KEGG) or literature-derived networks. Agilent's BridgeDB automatically links an annotated gene, protein or metabolite identifier in the experiment to the corresponding identifier used by the pathway database resulting in better annotation coverage for downstream analysis. We will highlight use cases merging transcriptomics with metabolomics data as well as a proteogenomics workflow highlighting metadata framework and correlation tools.
You May Also Like
FEB 17, 2026 | 8:00 AM

In cell therapy applications, commonly employed cell purification platforms for large-scale isolation of immune or stem cells separate cells based on a single cell surface antigen. Enrichmen...
FEB 18, 2026 | 8:00 AM

With advancing food allergy research and emerging therapies, new allergy testing requirements arise. In this context, Basophil Activation Testing (BAT) has emerged as an essential component...
FEB 18, 2026 | 1:00 PM

Energy-efficient filtration solutions that reduce hidden chemical exposure from benchtop work and lab equipment to improve overall laboratory safety...
FEB 19, 2026 | 7:00 AM
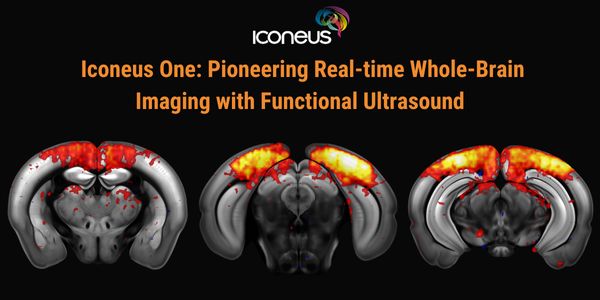
Discover how Iconeus One, the premier functional ultrasound (fUS) system for neuroscientists, is transforming brain function studies. Based on ultrafast plane-wave sonography, Iconeus One of...
FEB 19, 2026 | 8:00 AM

The collection of high-quality genomic DNA remains a major barrier in pediatric and neurodevelopmental research, particularly among children with autism spectrum disorder (ASD) and other neu...
FEB 23, 2026 | 9:00 AM
C.E. CREDITS

Explore decentralized liquid biopsy with SOPHiA GENETICS and MSK-ACCESS®, expanding access, improving outcomes, and accelerating precision oncology....
MAY 13, 2015 1:30 PM PDT
Share
Agilent platform for genomics, transcriptomics, proteomics and metabolomics based integrated biology: challenges and tools for multi-omics research
Presented at:
Genetics and Genomics Virtual Event Series 2015
Loading Comments...